
许可证和软件注册
Bandizip 许可证协议
如何注册 Bandizip
Bandizip 各版本功能对比
Bandizip MSE (微软商店版/Microsoft Store Edition)
如何得到收据
退款政策
如何取消注册Bandizip
Bandizip 付费版本的专属功能
如何使用密码管理器
如何使用压缩文件修复
如何使用密码恢复
如何在 Bandizip 预览压缩文件中的图像文件
压缩包中的反恶意软件扫描
How to test Bandizip Professional features before purchase
功能 & 技术用语
如何使用Bandizip来压缩文件
如何使用Bandizip来解压文件
如何使用智能解压至此
如何使用Bandizip对大文件进行分卷压缩
ZIP格式的UTF-8文件名
ZIPX格式
7z格式
ZPAQ 格式介绍
固实压缩
RAR格式介绍
ALZ和EGG格式介绍
如何使用快速拖放
如何使用多核压缩
如何使用高速压缩
如何用自定义文件名压缩文件
如何在不解压的情况下修改压缩文件
如何在不解压的情况下打开压缩文件内文件
如何对压缩文件里的文件进行修改和保存
如何给压缩文件设置密码
如何加密压缩文件内文件名
如何在删除压缩文件时将其移至回收站
如何压缩被其他进程占用的文件
如何使用并行解压功能
自动展开文件夹树
如何通过安全备份来防止数据损坏
如何检测压缩文件
如何将从网上下载的文件的Zone.Identifier信息复制到解压后的文件中
如何更改Bandizip主题颜色
如何导出和导入Bandizip设置
如何卸载Bandizip
如何更新Bandizip
命令行参数
Bandizip 安装命令行参数
Windows 10 on ARM 系统上的 Bandizip
故障排除
无法注册 Bandizip
无法访问用于购买 Bandizip 的邮箱账户
如何解决无法自动检测代码页
如何排除“当我在浏览器上下载压缩文件时,Bandizip 会自动打开它们”问题
压缩图标在文件资源管理器中不能正确显示
文件资源管理器不显示Bandizip的右键菜单。
Bandizip的右键菜单(上下文菜单)无法正常显示
解/压缩速度过慢
“错误 22": 运行 MacOS Catalina 的 Mac上,访达无法提取现有的 ZIP 压缩包。
Mac 访达无法解压已加密的 ZIP 压缩文件
如何使用非英文字符给压缩文件设置密码?
如何检测多个压缩文件
如何解决在Bandizip使用拖放功能时出现“参数错误”的问题
Bandizip 与便签同时使用,会导致程序停止。
在网络映射驱动器上无法打开压缩文件
分卷压缩文件无法被解压
Bandizip的bdzsfx.x86.sfx是什么文件?为什么被检测为恶意代码?
如何在 Linux 上使用 Wine 运行 Bandizip
ZIP格式的UTF-8文件名
UTF-8是一种用于存储支持多语言的Unicode字符串的编码方式。
Unicode和UTF-8是在上世纪90年代以后开发的,因此在80年代开发的ZIP格式不支持UTF-8。 然而,随着ZIP格式成为压缩文件的标准格式,ZIP格式也需要支持Unicode,于是开发出各种能够在ZIP文件处理UTF-8字符串的方法。
Bandizip支持两种方式:一、将文件名直接保存为UTF-8;二、将文件名保存为MBCS并在扩展字段再保存UTF-8文件名。
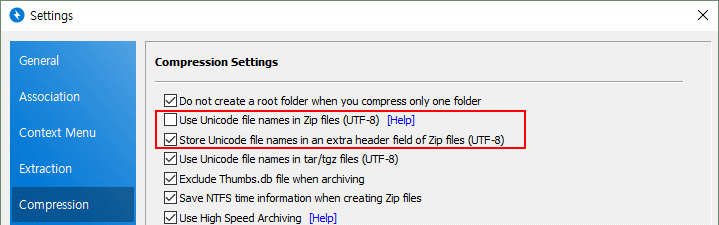
用ZIP压缩文件时,将文件名以Unicode(UTF-8)保存
这是将压缩在ZIP文件中的文件名以UTF-8保存的方式。 此为APPNOTE定义的标准UTF-8文件名保存方式,但有些压缩程序时常出现无法正确识别或因错误处理而无法正常显示文件名(出现乱码)的问题。 APPNOTE
用ZIP压缩文件时,将Unicode(UTF-8)文件名保存在扩展字段
这是将文件名保存为MBCS并在ZIP格式的扩展字段再保存UTF-8文件名的方式。 该方式也由APPNOTE定义为Info-ZIP Unicode Path Extra Field。 由于将文件名另外保存在扩展字段,ZIP文件大小可能会增大数十字节, 但基本上文件名保存为MBCS,因此兼容性更佳。
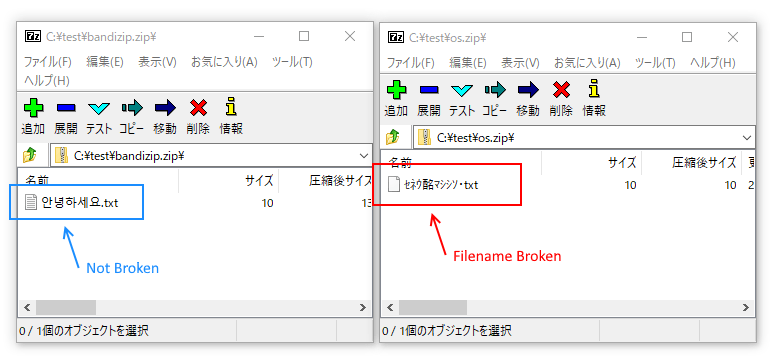
在使用不同语言的操作系统上,如果使用支持该扩展字段的压缩程序(7-Zip、WinRAR、WinZip),文件名不会出现乱码。
下图是在日文版Windows使用7-Zip打开在韩文版Windows压缩的文件的画面。
用TAR/TGZ压缩文件时,将文件名以Unicode(UTF-8)保存
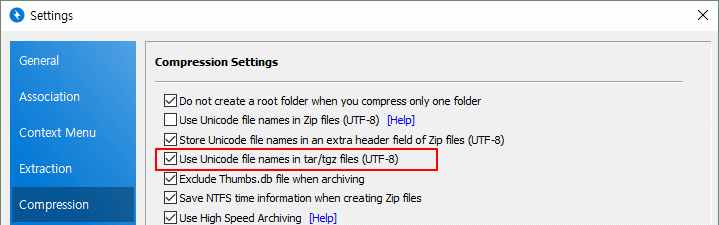
TAR或TGZ等格式是主要在Unix使用的压缩格式,Unix系统使用UTF-8文件名。启用该功能后压缩文件,即便文件名中含有韩文,也能在Unix系统上正常解压。
但Windows的有些程序可能无法正确识别TAR/TGZ格式的UTF-8代码页。